由于感觉现有爬虫用着不太方便 于是乎自己写了个爬虫
爬虫特点:
1'需要Java环境
2'需要cookie
3'支持关键字搜索爬取
4'可以以浏览数和收藏数为基础进行图片筛选
5'支持多线程下载
6'支持失败重试(直到下载成功为止)
7'图片下载完再保存(不存在下载一半中断的图片)
8'跳过已下载完的图片
9'根据画的数量选择是否跳过下载
10'自定义保存文件名称
11'支持uid爬取了!(2020.08.17)
12'支持任务列表
13'支持设置镜像站
14'支持设置代理
github地址: https://github.com/jht3QAQ/PixivSpider
使用方法:
1'下载release的PixivSpider.jar和config.properties.example 并放于同一文件夹下
2'配置config.properties.example并重命名为config.properties
其中cookie获取方法(以edge dev为例):
浏览器访问www.pixiv.net并登录,
打开F12开发者工具 点到网络标签 之后随便访问一个页面 找到含有www.pixiv.net的URL(如图)
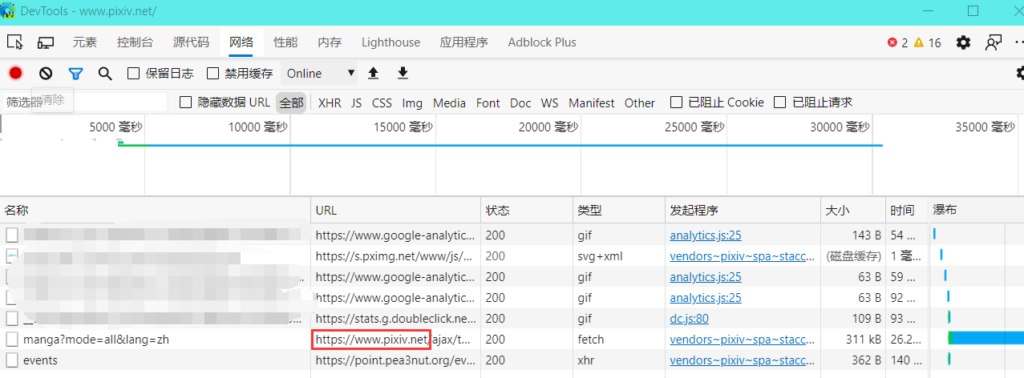
点击URL找到请求标头的Cookie项并复制
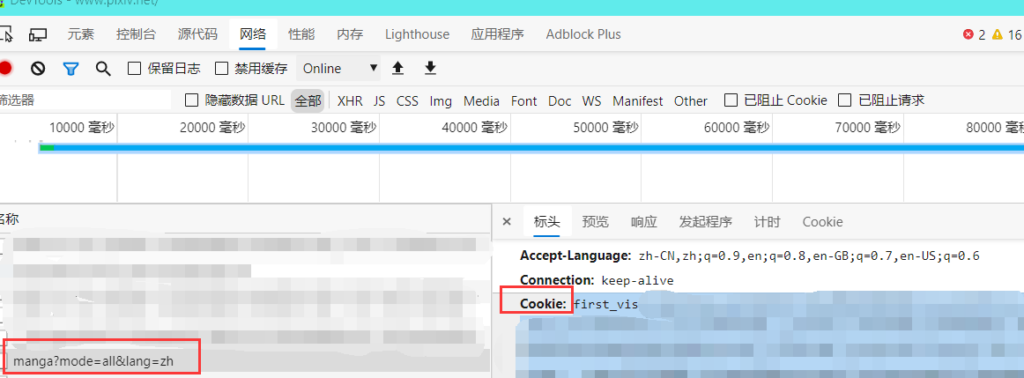
粘贴到config.properties的cookie处
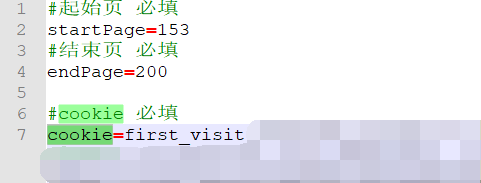
3.打开cmd并切换到jar所在目录下 输入java -jar PixivSpider.jar
最后附一张运行效果图:
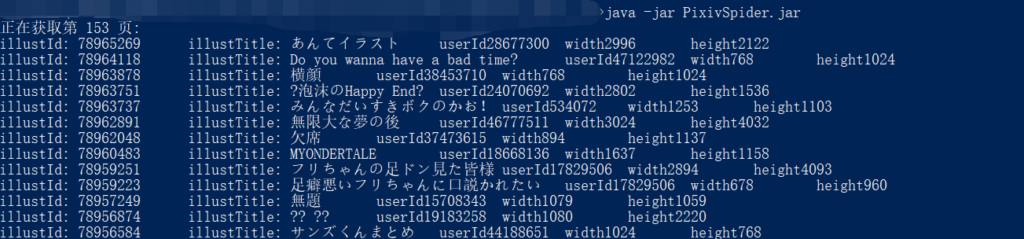
 终于更新辣,有空去试试w
终于更新辣,有空去试试w